
Split Testing: ROAS vs. Raising Budgets; a Foxwell Digital Interview with Maurice Rahmey
We caught up with Disruptive Digital’s Maurice Rahmey to talk through a split test he tweeted about to learn more about how he ran the test, why he did it, and what the results proved.
Here’s the Twitter thread:

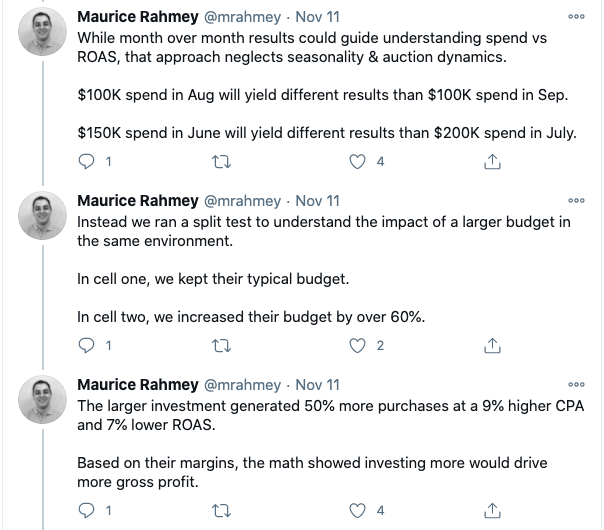
He continues his Twitter thread to talk about how the test worked and what exactly it meant, but we wanted to get to the bottom of his thought process in hopes it can help us all in our testing scenarios in the future.
Need the SparkNotes version? We got you:
werwerwerwerwerwer
Have the time to dive in? Watch the video or read the interview below.
MODERATOR, COURTNEY ALEXANDER: Hi, Maurice, thanks for joining me. My name is Courtney Alexander, and we wanted to get you on here to talk through with Foxwell Digital about a split test that you ran. But first, I want to introduce you: tell us who you are, what you do, and then we'll jump into the split test that you ran.
INTERVIEWEE, MAURICE RAHMEY: Sure. My name is Maurice Rahmey, I am the co-founder of an agency called Disruptive Digital that I started two and a half years ago with my business partner. We both worked at Facebook prior for about six or seven years each. And our goal is to work with clients that are trying to scale their businesses as long as they have some sort of an end goal. So for the most part, we're working with a lot of e-commerce businesses and subscription businesses. And generally speaking, the types of clients that we're working with are spending anywhere between $100,000 a month on the low end to $750,000 a month on the higher end, per client.
CA: Awesome. So you posted a tweet thread that really excited us and made us want to talk to you about it. So you ran a split test, but it was for testing ROAS for customer acquisition at scale. And so you did a split test to understand the impact of a larger budget in the same environment. So test one was what you mentioned in the Twitter thread was the normal budget. And then the second test was where you increased the budget by more than 60%. Can you kind of from a broad perspective, kind of explain this test? And what made you want to do it and kind of give us a little bit more insight into the test itself?
MR: Yeah, absolutely. So generally speaking, when we're working with businesses that we take on, they might be spending a little bit less and have a very high return on ad spend. But what that means is that they're going after a very qualified audience of people that have already been to the site, or sometimes they're burying existing customers. So, those numbers look really, really good, and then on top of that, a lot of the times they would have gotten those sales anyways, whereas in reality, the best way to kind of look at Facebook is not necessarily to think about it from what's the highest return on ad spend I can get, but more so, how can I scale as much as possible? This is because while you're getting a lower return on ad spend, and you're making less per customer, theoretically speaking, you end up making more money overall by focusing on going after after volume.
So, realistically, part of the way that we can kind of show this to clients is sometimes you'll see a client come in, and they have a 3X return on ad spend, but they've barely spent anything, because it's really hard to hit that number. Then, you look at the margins and back into the numbers and see that they made $5,000 on that particular effort last month and drove 100 customers, and instead of saying to them, “Hey, we're making $5,000 in profit and 100 customers, what about if we could look at this differently?”
So instead of making $5,000 with 100 customers, we make $5,000 in profit with 1,000 customers. Most people when they hear that, they agree that that actually makes sense, because at the end of the day, I'm still making the same amount of money, but I'm bringing in 10 times the amount of people that I was prior. So, in the test, we were trying to reposition to people how they think about the idea of profit from profit-per-customer to overall profit.
When they start to think about it that way, it allows us to look at the goals that we're achieving in a different way. This is because if we can show that we can scale, we can help you grow your business a lot quicker than previously.
CA: Could you talk a little bit about the seasonality, the auction dynamics that you discussed in your tweet, and specifically expanding upon what testing during different months and seasons may look like?
MR: Absolutely. I think that the important thing to understand is that we had a situation where our budget was capped, they had a very high ROAS goal, but instead of taking a situation where they would say, “All right, as long as we're getting to X, continue to invest,” they looked at it said, “We're gonna do $50,000, then the next month, we're gonna do $100,000.” And it was always these incremental dollars that were growing over time.
One of the challenges was that they weren't a client will look at that and say, “Oh, well, we doubled the budget, right?” And the return on ad spend was cut in half. But the problem with that approach is that you're not taking into account seasonality. If you're spending $50,000 in November, and then spend $100,000 in December, you’re going to have a situation where the performance might look worse in November when Black Friday, Cyber Monday aren't happening. As a result, you're not taking into account the seasonality that sometimes happens with businesses. And so realistically, the only way to understand how an increased budget is going to help you grow is by running it simultaneously in its own environment, compared to the budgets that you want to spend, because if you don't do that, you're always going to focus on a correlation versus, in this case, what should be causation.
CA: Got it. super interesting. So the specific split tests that you ran, how did you set it up? And how did you make sure that you weren't competing against yourself in the same account?
MR: We actually brought this idea to the Facebook team, because we felt that there was a lot of opportunity to grow. And so we worked with the marketing science team to kind of build this out. (In hindsight, there was no need for us to work with the Facebook team to make this happen, because a lot of the ways that this could have been done could have been done through the self serve split tools that Facebook already has).
The biggest component here is not necessarily just running two different budgets and comparing them, [but that] you have to have two mutually exclusive environments. And so, whatever you're running in cell A has to be exactly the same in cell B. And so we took that approach of saying, [in] cell A, we're going to have this level of prospecting, and this type of video, and then in cell B, we're going to do the same thing, except instead, what we're going to do is we're going to push up the budget by 60%, and understand how that's impacting the performance.
We didn't necessarily look at it and say, this got a 2X and this got a 3X. And so if we spend twice as much, we're going to get a 3X. It was looked at in terms of relative performance. And so if you're going from a 2X to a 3X in that particular month, you know, it's based on a percentage. So, in that case, we increased the ROAS by 50%, by spending X dollars more so, the entire time that we were focusing on the situation, bringing it to the client wasn't saying, if you spend X, you will get this return on ad spend, it WAS saying, “If we spent this percent more, we expect that you'll get this type of CPA or this type of relapse.” It's always done in relative terms.
CA: Got it. super interesting. So stepping out of the test just a little bit, if, let's say in the future, in a hypothetical situation, a client does agree that they're okay with that lower row as how would you suggest they scale?
MR: So I think it comes down to looking at what the numbers are prior to starting and saying, “If we're getting $5,000 today in profit, on a 3X return, that's when you're okay with getting $5,000 in profit, right?” So if that's the number that the client is okay with, we should back out the numbers to try and figure out and project what would allow us to still get the $5,000 that they’re okay with and profit.
But instead of aiming for getting that with lower spend and a higher profit per customer, instead, what we should do is focus on, how do we do that with volume. Because if we're acquiring new customers at the same rate, you're still making the same amount of money. In the long term, you're gonna end up making more on the lifetime value, but you're still making them the same up front, but now you have a lot more upside and opportunity to make more later, because you know that the lifetime value might be there.
CA: Interesting! So going back to the point about seasonality and making sure we're running these tests at the same time – obviously, there's anything that can happen in terms of seasonality. Do you think all seasons or times of year are good for this type of scaling? Or should you avoid times like Black Friday, Cyber Monday holiday season, etc?
MR: At the end of the day, you have to go into the test knowing two things: One, the test is not indicative of the results. At any point in earlier grades, it the test is indicative of results relatively. So if you were to spend twice as much at this time of the year, and you get a 50%, higher or lower ROAS, it will probably be the same, like a month later.
What does change, though, is that level of performance. Speaking of the idea of seasonality, where if you run a test in November, you might get different results than if you ran it in December. So anytime that you run a test, split test or lift test, you are going to get worse performance because of the fact that you're doing one of two things or both of these, in a holdout test, you're suppressing part of your audience. And so if you do that, instead of reaching 100% of your target audience, maybe you're reaching 80% and when you do that, your CPMs are going to rise because your supply of people that you can reach are going to be more cost prohibitive. Because of this, you're not actually reaching the entire environment.
Same thing with a split test: if you're going to take 50% of an audience and give them one budget, and 50% of your audience and give them another budget, you're not actually working within the normal Facebook environment to get the types of results that you might expect. And so you have to go in knowing that you're going to get worse performance, and you're ultimately just measuring the relative success between cell A and cell B. As a result, you have to think through when is the optimal time to kind of run a test like this. It doesn't make sense to do this during like your top sales period. I would say that it makes sense to do this to prepare for your top sales period.
If you don't believe that Facebook should work with scale, you would want to get this set up in advance of Black Friday or Cyber Monday, that's probably the best time to do it. Because that way, you're not going to lose out on that sales opportunity. While there's really no wrong time to do it, you want to do it in preparation for when you're actually going to have the best results possible in an uncontrolled environment versus in this test environment.
CA: Got it. So I know we talked about how their overall revenue is going to increase even if your ROAS goes down, but how does it make your client agree to the test, likely knowing or hypothesizing that their CPA would increase relies might decrease? How are they okay with being like the guinea pig for a test?
MR: In this particular situation, you have to say, we need to do this so that we can grow the business. And if we don't do this, we're never going to get to where you need to be. For us, when we take on an account, we need to know that we're gonna be able to get them to where they need to, to go and manage those expectations. I think that just comes down to an agency component of just managing those expectations. We wouldn't have worked with this account if we didn't believe that they were going to sign on to this [type of test or experiment]. In this case, we were aligned from the beginning that this would work.
I think it just comes down to managing those expectations and letting them know that if you want to do this, you are going to get worse results for the duration of the test, which might be three to six weeks. But the idea is we're going to come out of it, and it's going to be better for you in the long run.
CA: Are there any other challenges or intricacies or nuances that you faced during the split test?
MR: Our performance wasn't where we wanted to be; we weren't getting the results that we needed to necessarily get. But, the results were well under what we what we thought they were going to be. We expected dips, but we didn't expect the dips that we got.
What ended up happening was we we got the results that we wanted, not in terms of running the test for the full five weeks, but after three weeks, the client had seen enough that they knew that this was the right direction to go in. Ultimately, that was what the test was about; it wasn't necessarily about waiting five weeks to see what would happen, the goal was for the client to believe that this was the right approach.
In this particular situation, it was more than enough time, and it was still statistically significant that we could move forward with it. Did that impact our ability to run tests in the future? Yes and no. I think we're still gonna be able to do them, but I think the expectations we will set will be lower than what happens this time around. Other than that, everything was managed as expected.
CA: Awesome. Is there anything else that you definitely want to share that was interesting about this split test? So that would help other ad buyers, other people wanting to run split tests? Is there anything else that you wanted to add that maybe I haven't asked yet?
MR: Any time you run a split test or a hold out or do any sort of experiment, you just want to make sure that you're going in with the hypothesis and not just kind of testing for testing sake.
I think sometimes that happens, if you have a big sweeping idea. It's really worth it, to split test, because you don't want to say that some sort of component that you're doing works when in reality, again, it might be that idea of causing, like correlation where it's just because you did it during this time period versus causation where it might actually be some change that you made, that had that impact.
Sometimes, people mistake correlation for causation, when that's really not the case, or they test things that aren't actually going to be meaningful for the business, so you have to go in with with these big hypotheses if you're going to do it. Also, small tests are not going to grow a business as much as kind of thinking through like these big sweeping cuts, like thinking about increasing investment by 60, or 70%.
CA: Got it. That's all the questions I had for you today. Thank you so much for joining us and for talking through this. And if anyone has questions, they can reach out to you on Twitter at @mrahmey.